Język chiński (standardowy mandaryński), choć swoją powszechnością nie dorównuje językom takim jak angielski, hiszpański czy niemiecki, cieszy się w Polsce stosunkowo sporą i wciąż rosnącą popularnością, a jego nauka dostępna jest nie tylko w ofercie prywatnych szkół językowych, ale też ośrodków akademickich, a nawet niektórych szkół średnich. Dla wielu największym wyzwaniem w opanowaniu wymowy języka chińskiego są tony i być może pojedyncze głoski niewystępujące w języku polskim. Tymczasem, skupiając się na tym, co dla nas najbardziej egzotyczne, nie możemy zapomnieć, że zaczynając naukę tego orientalnego języka, warto pochylić się również nad dźwiękami, które są jakby nieco mniej obce, które być może wydają się łatwe i które, w otoczeniu tylu „ciekawszych” głosek, zdają się być po prostu niewarte naszej uwagi…
Kontrast dźwięczności a parametr VOT
Powszechny w językach świata kontrast dotyczący dźwięczności jest silnie zależny od preferencji danego języka. Oznacza to, że choć języki mogą posiadać ten sam fonologiczny kontrast, to tak naprawdę wcale nie muszą go identycznie realizować.
Aby lepiej zrozumieć istotę dźwięczności, warto posiadać podstawową wiedzę z zakresu fonetyki akustycznej. Poniżej pokrótce opisano najważniejsze, istotne dla omawianego w niniejszym artykule tematu, terminy z tej dziedziny.
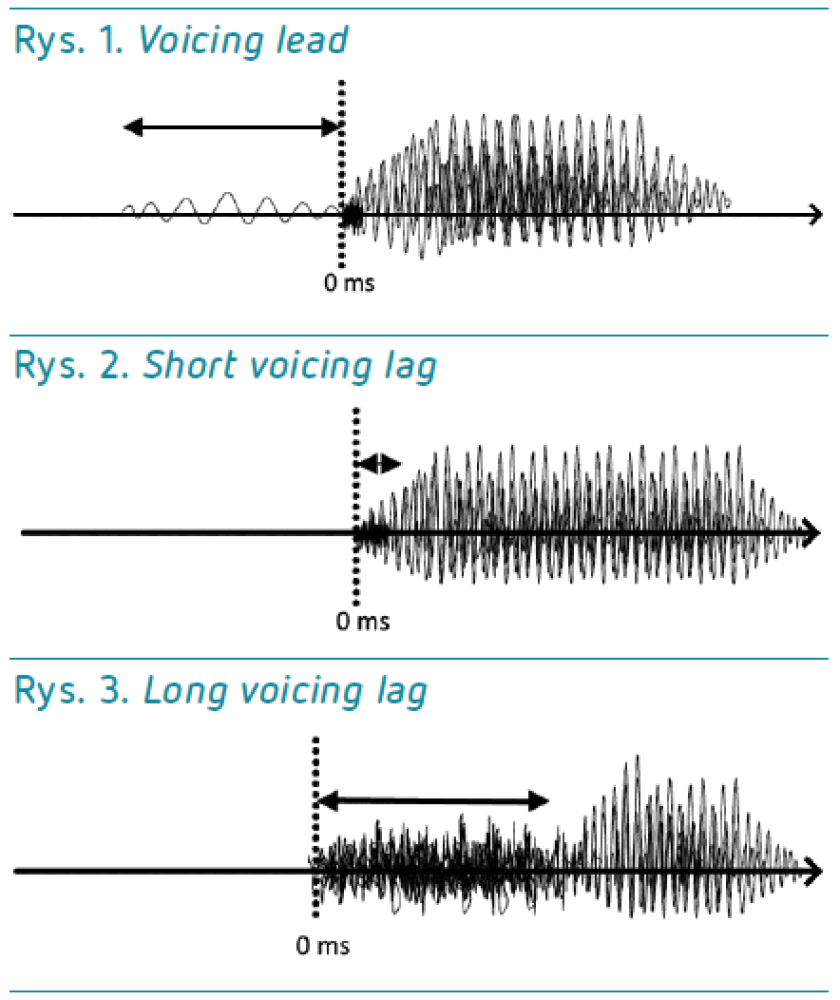
Dźwięki to fale, które mogą być przedstawiane wizualnie. Takie reprezentacje graficzne – w postaci spektrogramów lub oscylogramów – pozwalają lepiej opisać i zrozumieć różnice pomiędzy dźwiękami. Istnieje szereg parametrów, które są istotne przy analizie dźwięków, jak na przykład częstotliwość, czas trwania, natężenie. W klasyfikowaniu spółgłosek zwarto-wybuchowych jako dźwięczna–bezdźwięczna pomocny okazuje się parametr VOT (ang. voice onset time)1. W uproszczeniu jest to czas między momentem, gdy zaczynamy wypowiadać spółgłoskę, a momentem, gdy zaczynamy wydobywać samogłoskę. Czas ten, jak można się domyślić, jest bardzo krótki – mierzony w milisekundach (ms). Gdy VOT wynosi 0 ms, oznacza to, że drgania głosowe (dźwięczność) i wybuch spółgłoski zaczynają się praktycznie jednocześnie.
W większości języków spółgłoski zwarto-wybuchowe są realizowane zazwyczaj na dwa z trzech poniższych sposobów:
- Voicing lead (dźwięczność wyprzedzająca, ok. –30 ms VOT lub więcej) – wartości VOT są ujemne, gdyż drgania periodyczne pojawiają się już przed wybuchem spółgłoski (np. polskie /b/). Drgania te są widoczne jako koncentracja harmonicznej energii na niskich poziomach (rys. 1.)
- Short voicing lag (krótkie opóźnienie dźwięczności, krótkie wartości, ok. 0 ms do +30 ms VOT, – drgania periodyczne rozpoczynają się w momencie lub tuż po wybuchu spółgłoski (np. polskie /p/), (rys. 2.)
- Long voicing lag (długie opóźnienie dźwięczności, długie wartości, ok. +50 ms lub więcej VOT, – drgania głosowe zaczynają się znacznie później niż wybuch spółgłoski. Po wybuchu może wystąpić cisza (Klatt 1975) lub faza aspiracji, co można akustycznie zarejestrować jako szum w okolicach drugiego i trzeciego formantu dźwięku (Lisker i Abramson 1964: 386). W skrócie, długie opóźnienie dźwięczności oznacza, że dźwięczność i wybuch spółgłoski są oddzielone znacznym czasowym odstępem (np. chińskie /p/); (rys. 3.)
Dźwięczność w językach polskim i chińskim
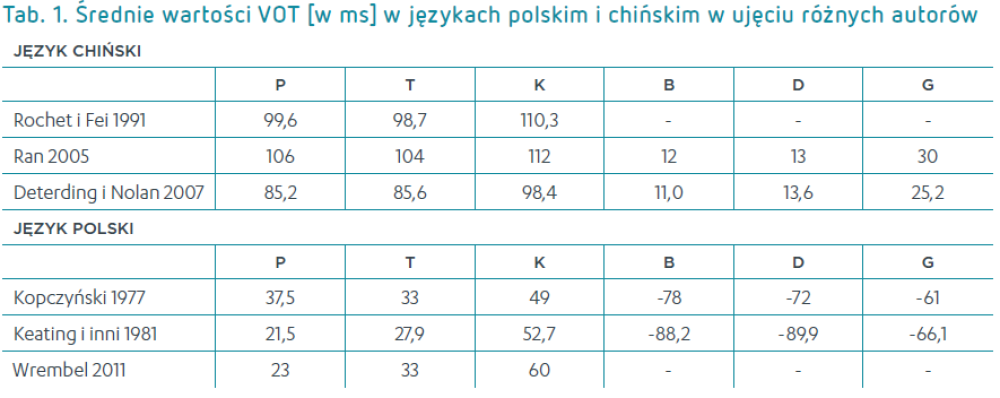
Jak wspomniano na początku, języki mogą posiadać ten sam fonologiczny kontrast, ale realizować go w różny sposób. Tak też jest w przypadku języków polskiego i chińskiego2. W języku polskim kontrast dźwięczności reprezentowany jest przez spółgłoski dźwięczne o ujemnym VOT (voicing lead) i spółgłoski bezdźwięczne nieaspirowane o krótkich dodatnich wartościach VOT (short lag). W języku chińskim – przez spółgłoski bezdźwięczne nieaspirowane (short lag) i bezdźwięczne aspirowane o bardzo długich dodatnich wartościach VOT (long lag). Jednocześnie na uwagę zasługuje fakt, że polskie spółgłoski short lag mają na ogół nieco dłuższe wartości VOT niż chińskie spółgłoski short lag, których wartości są bliższe 0 ms. Średnie wartości VOT w ujęciu różnych autorów znajdują się w tabeli 1.
Badanie
Pinyin (拼音) jest współcześnie najpopularniejszym zapisem fonetycznym (wykorzystującym alfabet łaciński) języka chińskiego, stosowanym w pierwszych klasach szkół chińskich i w nauczaniu cudzoziemców. Choć dla uczących się jest nieocenioną pomocą, może wzbudzać też pokusę do spolszczania niektórych głosek, zwłaszcza jeśli różnica artykulacyjna pomiędzy głoskami reprezentowanymi w dwóch językach przez te same znaki graficzne nie została dostatecznie jasno przedstawiona na początkowych etapach przyswajania języka. Sytuacja taka może mieć miejsce w przypadku par spółgłosek zwarto-wybuchowych, szczególnie gdy uczący się korzysta z podręczników anglojęzycznych, które to przeważnie traktują chińskie /p b t d k g/ jako ekwiwalentne angielskim /p b t d k g/ – co nie jest bezzasadne, gdyż obydwa te języki realizują kontrast dźwięczności w zbliżony sposób. Tymczasem badania jasno pokazują, że w przypadku Polaków ćwiczenia w percepcji i realizacji spółgłosek zwarto-wybuchowych short lag–long lag nie mogą zostać zaniedbane i pominięte. Badania nad percepcją kontrastu dźwięczności w językach angielskim (Rojczyk 2011) oraz chińskim (Knoll 2019) przez Polaków pokazują, że o ile spółgłoski /p t k/ nie stwarzają problemu, ponieważ wartości długie VOT, niewykorzystywane w polskim, są łatwo rozpoznawane przez Polaków jako bezdźwięczne, o tyle /b d g/, jako że mają wartości VOT zbliżone do polskich /p t k/, mogą być rozpoznawane jako bezdźwięczne. Jednocześnie badania te pokazują również, że odpowiedni trening fonetyczny pozwala Polakom na stworzenie kategorii dźwięczności wzdłuż wartości dodatnich VOT, tak że uczący się języka na poziomie zaawansowanym są w stanie kategoryzować wartości dodatnie VOT w sposób zbliżony do rodowitych użytkowników. Jeżeli chodzi o realizację kontrastu short lag–long lag, aspiracja u Polaków uczących się języka angielskiego nierzadko jest – w porównaniu z native speakerami – niedostatecznie długa (Waniek-Klimczak 2005; Sypiańska 2021), zaś spółgłoskom /b d g/ towarzyszy charakterystyczna dla języka polskiego, wyprzedzająca dźwięczność (Schwartz 2020).
W niniejszym artykule pokażę, jak osoby dorosłe, które nie rozpoczęły jeszcze nauki języka chińskiego, percypują i realizują kontrast dźwięczności w kategorii spółgłosek zwarto-wybuchowych w tymże języku3.
Uczestnicy
W badaniu udział wzięło 20 Polaków: 12 mężczyzn i 8 kobiet. Wszyscy byli studentami I i II roku studiów drugiego stopnia (magisterskich) na kierunkach niefilologicznych, w wieku od 23 do 26 lat (średnia: 23,4; odchylenie stand.: 0,94). Badani nigdy wcześniej nie uczyli się języka chińskiego4; nikt nie miał historii chorób słuchu lub mowy ani nie cierpiał na żadne choroby słuchu w momencie badania.
Materiał
Na potrzeby badania utworzono listę 18 możliwie jak najbardziej podobnych do siebie fonetycznie jednosylabowych słów w trzech językach: polskim, chińskim i angielskim. Badane spółgłoski znajdowały się w nagłosie (gdyż tylko w takim kontekście w języku chińskim występują), zaś poszczególne sylaby miały struktury CV(V) oraz CVC, tj. składały się z: (i) spółgłoski zwarto-wybuchowej, (ii) samogłoski /a/ lub /æ/, (iii) spółgłoski lub kolejnej samogłoski (drugiej części dyftongu).
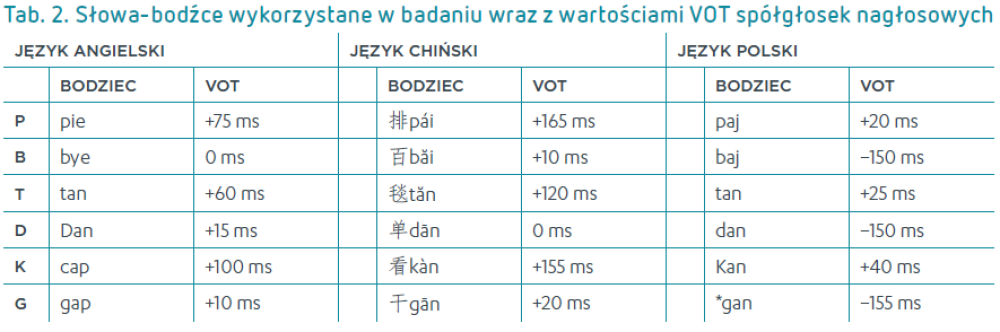
Bodźcami wykorzystanymi w eksperymencie były nagrania wybranych 18 słów. Dla języków chińskiego i angielskiego użyto nagrań z podręczników, zaś bodźce polskie zostały zarejestrowane przez Polaka. Bodźce w językach angielskim i polskim były artykułowane z neutralną intonacją, zaś w przypadku języka chińskiego dwie sylaby miały ton wysoki, jedna wznoszący, dwie opadająco-wznoszący, a jedna ton opadający. Dla każdego bodźca za pomocą programu Praat (Boersma i Weenink 2019) dokonano pomiaru VOT nagłosowej spółgłoski, zaokrąglając pomiary do najbliższych 5 ms. Słowa-bodźce, które zostały zaprezentowane uczestnikom wraz z wartościami VOT spółgłosek nagłosowych, znajdują się w tabeli 2.
Przebieg
Każdy z uczestników przystępował do badania indywidualnie i otrzymał informację w języku polskim o jego przebiegu. Uczestnicy dostali karty odpowiedzi i zostali poproszeni o zakreślenie litery (głoski), która znajduje się na początku każdej z 18 usłyszanych sylab – wybierali pomiędzy: P, B, T, D, K, G oraz H. Przed prezentacją właściwego materiału wykonali próbę na słowie nieistotnym dla celów badania. Uczestnicy słuchali materiału przez wysokiej jakości słuchawki nauszne z wbudowanym mikrofonem. Kolejność prezentacji bodźców została automatycznie wymieszana. Były one rozdzielone trzysekundową pauzą, a każdy z nich prezentowano jednokrotnie. Po zakończeniu pierwszej części uczestnicy oddawali karty odpowiedzi i przystępowali do drugiego etapu badania, podczas którego ponownie odsłuchiwali te same nagrania, a ich zadaniem było jak najbliższe oryginałowi powtórzenie każdej z 18 usłyszanych sylab. Bodźce zostały automatycznie wymieszane, rozdzielone czterosekundową pauzą, a każdy z nich prezentowano jednokrotnie. Realizacje uczestników były nagrywane, a nagrania każdorazowo przetwarzane do pliku WAV i przechowywane do dalszej manipulacji na twardym dysku komputera.
Po zakończeniu badania odpowiedzi uczestników przeniesiono do programu MS Excel, a uzyskane w czasie eksperymentu nagrania zostały przeanalizowane w programie Praat 6.0.45. Do analiz statystycznych wykorzystano program Minitab, a wykresy sporządzono w programach Minitab i MS Excel. Aby sprawdzić, czy wartości średnie/środkowe VOT uczestników różniły się istotnie statystycznie od wartości modelowych, wykonano test t dla jednej próby / test Wilcoxona dla par obserwacji, uprzednio sprawdziwszy normalność rozkładu.
Wyniki i analiza
Percepcja
Silnie aspirowane spółgłoski /p t k/ uczestnicy konsekwentnie rozpoznawali jako bezdźwięczne. Wskazania dotyczące dźwięczności spółgłosek /b d g/ były nieco mniej jednoznaczne, choć na ogół częściej percypowano je jako dźwięczne (38 razy, 63,3%). Dokładniejsza analiza pokazała, że liczba bodźców słyszanych jako dźwięczne wyniosła 1,1 (odchylenie stand.: 1,02), przy czym najmniej jednoznaczne były wskazania dla /b/ o 10 ms VOT (rys. 4). Analiza indywidualna pokazała, że ponad połowa grupy (13 osób, 65%) wskazała na dźwięczność dwóch lub wszystkich bodźców (rys. 5).


Imitacja
Bardzo długa aspiracja spółgłosek /p t k/ na ogół była bardzo wiernie imitowana przez uczestników, których produkcje oscylowały wokół wartości od +99 ms do +136 ms VOT (mediana: 136 ms) i z punktu widzenia statystyki nie odbiegały istotnie od wartości modelowych (zob. rys. 6, tab. 3).
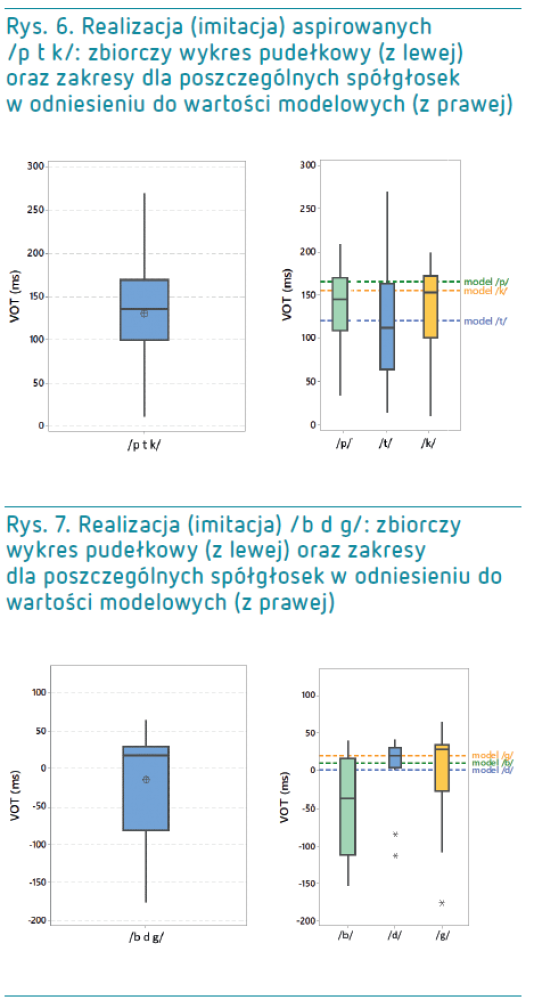

Spółgłoski /b d g/ (o wartościach modelowych +10, 0 i 20 ms VOT) ogółem zostały wyartykułowane z VOT o nieujemnych wartościach 43 razy (71,7%). Wartości VOT znajdowały się w zakresie od −82 ms do +30 ms VOT (mediana = 17 ms). Statystycznie realizacje nie odbiegały istotnie od realizacji modelowych, jednak uczestnicy nierzadko, czy to dodawali więcej aspiracji, czy to artykułowali spółgłoski z pełną dźwięcznością (ujemnymi wartościami VOT, co widać najwyraźniej w przypadku /b/; zob. rys. 7, tab. 4).

Omówienie i implikacje dydaktyczne
W niniejszym artykule pokrótce omówiono, w jaki sposób dorośli Polacy percypują i realizują (częściowo) nowy, niewykorzystywany w ojczystym języku kontrast dźwięczności. Mimo że może się wydawać, iż w transkrypcji Pinyin znajduje się wiele innych „ciekawszych” dźwięków, wyniki przedstawionego badania pokazują, że percepcja i realizacja chińskich spółgłosek zwarto-wybuchowych powinny być ćwiczone już od pierwszych lekcji tego języka, a uczących się należy uświadamiać na temat różnic pomiędzy językami. W przypadku pracy z dorosłym uczniem – a często to właśnie te osoby rozpoczynają naukę chińskiego – wartościowym może być korzystanie z programów takich jak Praat, dzięki którym uczniowie mogą dźwięczność/bezdźwięczność „zobaczyć” i w stosunkowo prosty sposób zweryfikować swoją wymowę. Szczególną uwagę należy zwrócić na spółgłoski short lag o krótkich dodatnich wartościach VOT, których zapis Pinyin (b, d, g) może uczącym się sugerować, że są one odpowiednikami polskich spółgłosek /b d g/. Innymi słowy, należy przede wszystkim zadbać o to, by głoski te nie były wymawiane z pełną (wyprzedzającą) dźwięcznością charakterystyczną dla kategorii polskich spółgłosek dźwięcznych. Jednocześnie należy mieć na uwadze, że polskie spółgłoski zwarto-wybuchowe mają na ogół nieco wyższe wartości VOT w porównaniu ze spółgłoskami chińskimi, wobec czego polskiej kategorii bezdźwięcznej również nie należy traktować jako ekwiwalentnej chińskim /b d g/ – a, jak wynika z obserwacji autorki, u Polaków posługujących się językiem chińskim zdarza się to wcale nie rzadko. W ćwiczeniach percepcyjno-artykulacyjnych nie można jednak pomijać grupy spółgłosek aspirowanych, które, choć do naśladowania dość łatwe, w mowie spontanicznej mogą aspirację nadmiernie wytracać.
W załączniku przedstawiono przykładowy scenariusz zajęć (na jedną jednostkę lekcyjną – 45 min – w szkole średniej lub wyższej) poświęconych spółgłoskom zwarto-wybuchowym. Zaproponowano wykorzystanie wspomnianego w artykule programu Praat. Oczywiście użycie takiego narzędzia wymaga od nauczyciela przygotowania, a być może nawet dokształcenia w zakresie fonetyki akustycznej. Choć można by z tego zrezygnować, to jednak, wbrew możliwym obawom, opanowanie dokonywania pomiaru VOT nie powinno przysporzyć wielu trudności. Co więcej – może przynieść wymierne korzyści uczącym się pod okiem nauczyciela studentom lub uczniom. Dzięki generowanym w programie wizualnym reprezentacjom uczniowie nie są bowiem zdani jedynie na percepcję słuchową: takie graficzne odwzorowanie dźwięków umożliwia im lepsze zrozumienie struktury fonetycznej oraz pozwala na precyzyjniejszą – bardziej obiektywną – analizę swojej wymowy, co z kolei powinno przyczynić się do szybszego i lepszego opanowania przez nich chińskich spółgłosek zwarto-wybuchowych. Jednak bez względu na to, czy zdecydujemy się na swoich lekcjach wprowadzać elementy fonetyki akustycznej, czy nie, nie zapominajmy o wyczulaniu swoich studentów na różnice między dźwiękami polskimi i chińskimi, zwłaszcza jeśli korzystamy z podręczników skierowanych do osób anglojęzycznych.
1 Parametr ten został wprowadzony przez Leigha Liskera i Arthura Abramsona (1964); jest rozumiany jako pomiar czasu trwania upływającego „pomiędzy wybuchem, który sygnalizuje koniec zwarcia spółgłoski, a początkiem periodyczności, która odzwierciedla wibrację krtaniową” (Lisker i Abramson 1964: 422).
2 Rozumianego w tym artykule jako standardowy język chiński (mandaryński), będący językiem oficjalnym Chińskiej Republiki Ludowej.
3 Przedstawiona zostanie część wyników badań przeprowadzonych przez autorkę na potrzebę pracy doktorskiej pt. Percepcja i realizacja fonologicznego kontrastu dźwięczności w angielskich i chińskich spółgłoskach zwarto-wybuchowych przez Polaków.
4 Uczestnicy mieli jednak już doświadczenie z podobnym kontrastem – wszyscy zdali egzamin maturalny z j. angielskiego na poziomie podstawowym (A2/B1 wg skali CEFR).
Bibliografia
Boersma, P., Weenink, D. (2019), Praat: Doing Phonetics by Computer [program komputerowy], wersja 6.0.45, <www.praat.org>, [dostęp: 24.06.2019].
Deterding, D., Nolan, F. (2007), Aspiration and Voicing of Chinese and English Plosives, „Proceedings of the 16th International Congress of Phonetic Sciences”, s. 385–388.
Keating, P.A., Mikoś, M.J., Ganong, W.F. III (1981), A Cross–Language Study of Range of Voice Onset Time in the Perception of Initial Stop Voicing, „Journal of the Acoustical Society of America”, nr 70, s. 1261–1271.
Knoll, K. (2019), “Dùzi bǎole” or “tùzi pǎole”?: the Perception of Mandarin Word-initial Stops by Poles, [w:] A. Solska, I. Kida (red.), Oriental Encounters: Language, Society, Culture, s. 34–50, Katowice: Wydawnictwo Uniwersytetu Śląskiego.
Kopczyński, A. (1977), Polish and American English Consonant Phonemes. A Contrastive Study, Warszawa: PWN.
Lisker, L., Abramson, A.S. (1964), A Cross–Language Study of Voicing in Initial Stops: Acoustical Measurements, „Word”, nr 20(3), s. 384–422.
Ran, Q.B. (2005), Experimental Studies on Chinese Obstruent Consonants: with the Emphasis on Standard Chinese, [praca doktorska], Tianjin: Nankai University.
Rochet, B.L., Fei, Y. (1991), Effect of Consonant and Vowel Context on Mandarin Chinese VOT: Production and Perception, „Canadian Acoustics”, nr 19(4), s. 105.
Rojczyk, A. (2011), Perception of the English Voice Onset Time Continuum by Polish Learners, [w:] J. Arabski, A. Wojtaszek (red.), The Acquisition of L2 Phonology, Bristol, Buffalo, Toronto: Multilingual Matters.
Schwartz, G. (2020), Asymmetrical Cross-Language Phonetic Interaction Phonological Implications, „Linguistic Approaches to Bilingualism”, nr 12(2), s. 103–132.
Sypiańska, J. (2021), Production of Voice Onset Time (VOT) by Senior Polish Learners of English, „Open Linguistics”, nr 7(1), s. 316–330.
Waniek-Klimczak, E. (2005), Temporal Parameters in Second Language Speech: An Applied Linguistics. Phonetics Approach, Łódź: Wydawnictwo Uniwersytetu Łódzkiego.
Wrembel, M. (2011), Cross–Linguistic Influence in Third Language Acquisition of Voice Onset Time, „Proceedings of the 17th International Congress of Phonetic Sciences”, s. 2157–2160.
Artykuł został pozytywnie zaopiniowany przez recenzenta zewnętrznego „JOwS” w procedurze double-blind review.
Załącznik ze scenariuszem lekcji w załączonym pliku pdf z pełną wersją artykułu.




