Wobec cyfryzacji edukacji językowej w dobie pandemii spowodowanej koronawirusem wspomagane komputerowo metody i techniki nauczania zyskały drugie życie. Nieco zapomniane quizy językowe o behawiorystycznym charakterze czy nawet proste przywoływanie odpowiedników słów stały się podstawą do przygotowywanych na potrzeby zdalnych lekcji materiałów w serwisach typu Quizlet, Learning Apps, Duolingo czy Wordwall. Jest to zatem dobry moment na przemyślane wykorzystywanie danych i funkcjonalności narzędzi korpusowych. Nie o podstawach językoznawstwa korpusowego w praktyce nauczycielskiej traktuje jednak niniejszy artykuł1. Odnoszę się tu nie do korpusów gotowych, ale raczej „szytych na miarę” (do-it-yourself corpora), przydatnych w rozwijaniu sprawności pisania na poziomie średnio- i zaawansowanym (B1/B2 i C1).
O korpusach językowych w nauczaniu sprawności pisania
Wiele publikacji wskazuje na zalety stosowania procedur językoznawstwa korpusowego w nauczaniu języków obcych (Lewandowska-Tomaszczyk 2005). Są one widoczne w szczególności podczas wykorzystywania dużych lub bardzo dużych kolekcji tekstowych (Bernardini 2000; de Schryver 2002), rozwijania sprawności pisania zarówno u początkujących uczniów (Gaskell i Cobb 2004; Yoon i Hirvela 2004), jak i na wyższych poziomach zaawansowania (Chambers i O’Sullivan 2004), a także przy wspomaganiu nauczania gramatyki w fazie prezentacji struktur (Hadley 2002) oraz formułowaniu przez uczniów reguł gramatycznych (St. John 2001). Procedury językoznawstwa korpusowego mają zastosowanie także w procesie nabywania leksyki z kontekstu pisanego (Cobb 1997; Cobb 1998; Cobb i in. 2001; Horst i in. 2005), wspomagania utrwalania leksyki (Lewandowska-Tomaszczyk 2001; Leńko-Szymańska 2001, 2005) oraz wspomagania autonomii ucznia poprzez realizację treningu strategicznego (Kennedy i Miceli 2001; St. John 2001; Chambers 2005). Rekomendując stosowanie procedur językoznawstwa korpusowego w klasie językowej, badacze ci wskazują jednocześnie na takie problemy, jak możliwość „utonięcia w danych”, trudności interpretacji konkordancji, konieczność stosowania bardziej zaawansowanej składni dla zapytań wykraczających poza proste sprawdzenie pojedynczych słów, trudności ze zrozumieniem interfejsów czy koszt dostępu do korpusów gotowych.
W procesie kształtowania sprawności pisania, zwłaszcza w kontekstach autonomicznych, dużo bardziej przydatne od korpusów gotowych będą kolekcje tekstowe tworzone przez nauczyciela, samego ucznia lub grupy uczniów w odpowiedzi na konkretne potrzeby klasy (Lee i Swales 2006). Takie „szyte na miarę” minikorpusy (do-it-yourself corpora) są ważną pomocą dla nauczyciela w takich sytuacjach, gdy uczniowie mają specyficzne potrzeby wynikające z wąsko sprecyzowanego celu uczenia się, gdy istniejące korpusy nie odzwierciedlają w należytym stopniu danych typów tekstów lub dziedzin życia (Tribble 1997), lub też gdy celem nauczyciela jest odzwierciedlenie w większym stopniu języka potocznego, mówionego czy konkretnej odmiany geograficznej (Crystal 2005).
Nauczanie sprawności pisania, zwłaszcza w ramach podejścia produktowego (writing as a product), opiera się w dużej mierze na analizie wzorców tekstowych i ich reprodukcji. Zgromadzenie przykładowych prac pisemnych w obrębie gatunków tekstowych, wymaganych np. na egzaminie ósmoklasisty czy egzaminie maturalnym, i skompilowanie w ten sposób minikorpusu pozwoli na prezentowanie uczniom zarówno oczekiwanych, jak i błędnych przykładów użycia typowych struktur gramatycznych i środków leksykalnych.
O ile jednak tworzenie minikorpusu językowego na podstawie prac uczniów z poprzednich lat może być stosowane przez nauczyciela tylko w formie prezentacji i ćwiczeń z uwagi na ograniczenia praw autorskich, o tyle dodawanie przez uczniów własnych tekstów w celu analizy popełnionych w nich błędów czy porównywanie swoich dzieł z modelem przy pomocy narzędzi analizy tekstowej opisanych poniżej jest już dostępne dla każdego uczącego się od poziomu B1. Warto zatem tworzyć i wprowadzać proste ćwiczenia w tym zakresie na podstawie napisanych i sprawdzonych prac pisemnych uczniów – pozwoli im to lepiej zrozumieć, w jakim stopniu udało im się sprostać zadaniu i jak powinien wyglądać tekst zgodnie z kryteriami wybranego gatunku.
Ogólnodostępne narzędzia konkordancyjne
O ile wykorzystanie korpusów językowych w procesie nauczania gramatyki i leksyki może opierać się na odpowiednio wybranych przykładach użycia wyekstrahowanych z gotowych korpusów językowych2, o tyle proces nauczania sprawności komunikacji pisemnej wymaga doboru tekstów do analizy przez nauczyciela. Często będą to teksty reprezentatywne dla danej dziedziny, modele gatunków tekstowych określone przez wymagania egzaminacyjne czy prace na ten sam temat napisane przez uczniów (jednej klasy lub zbierane na przestrzeni lat). Wykorzystanie tekstów własnych, odpowiednio wyselekcjonowanych przez nauczyciela, wziąwszy pod uwagę możliwości i oczekiwania uczniów oraz zakładane cele dydaktyczne, wymaga narzędzi pozwalających na dodawanie tekstów i ich przeszukiwanie w odpowiedzi na zadane pytania językowe, tworzenie list frekwencyjnych czy określanie stopnia powtarzalności językowej. Poniżej scharakteryzuję kilka ogólnodostępnych narzędzi do samodzielnego tworzenia minikorpusów językowych i wykonywania analiz tekstowych. Nie są to gotowe rozwiązania, które zastąpią ocenianie prac pisemnych przez nauczyciela, ale raczej dostarczą danych liczbowych, np. na temat stopnia powtarzalności leksyki w różnych tekstach czy objętości tekstu napisanego z użyciem kilku/kilkunastu najczęściej używanych słów. Tego typu dane posłużą nauczycielowi w fazie wstępnej przed pisaniem (pre-writing), umożliwiając mu przewidywanie problemów oraz budowanie świadomości językowej ucznia, a także podczas sprawdzania prac pisemnych, ułatwiając uzasadnienie oceny poprawności i bogactwa językowego.
Compleat Lexical Tutor (lextutor.ca)
Przygotowane przez Toma Cobba z Uniwersytetu Quebecu w Montrealu narzędzie dostępne w formie internetowych formularzy może na pierwszy rzut oka wydawać się mało czytelne i trudne w użyciu, dlatego wygodniej korzystać z konkretnych podstron wymienionych poniżej w celu analizy przygotowanych tekstów autentycznych lub tych napisanych przez uczniów.
- Hypertext Builder (www.lextutor.ca/hyp/1), dostępny dla języka angielskiego i francuskiego, łączy wprowadzony tekst z wybranym korpusem, dzięki czemu podwójne kliknięcie każdego słowa otworzy zestaw konkordancji zawierających dany wyraz;
- Concord Writer (www.lextutor.ca/conc/write) działa podobnie jak Hypertext Builder: w trakcie tworzenia tekstów po podwójnym kliknięciu napisanego słowa uczeń otrzyma zestaw konkordancji, które pomogą mu zastosować odpowiednią kolokację;
- Text-Lex Compare (www.lextutor.ca/cgi-bin/tl_compare/index.pl) pozwala na bardzo dokładne porównanie podobnych tekstów (np. prac wszystkich uczniów napisanych na ten sam temat). Po wprowadzeniu tekstów (aż do 25 plików) generowany jest bardzo dokładny raport w języku angielskim, pokazujący w szczególności stopień powtarzalności leksykalnej (Lexical Recycling Index), listy słów współdzielonych przez poszczególne teksty oraz unikalnych dla każdego z nich;
- Coverage Calculator (www.lextutor.ca/cover) odnosi się do gotowych korpusów zebranych przez Toma Cobba (m.in. British National Corpus, Brown Corpus, COCA czy LOB Corpus), pozwalając nauczycielowi lub uczniowi na wprowadzenie własnej listy słów celem sprawdzenia częstotliwości ich występowania w znanych korpusach. Dzięki temu można zweryfikować własne przewidywania dotyczące częściej lub rzadziej używanych synonimów;
- Frequency (www.lextutor.ca/freq) to podstawowe narzędzie do analizy tekstowej – po wprowadzeniu tekstu generowana jest lista frekwencyjna, pokazująca nie tylko ranking i liczbę poświadczeń, ale również, co istotne, ich skumulowany odsetek, dzięki czemu uczeń może zobaczyć, z jak wielu (lub częściej – niewielu) powtarzających się słów składa się napisany przez niego tekst.
Rys. 1. Lista frekwencyjna dla wprowadzonego tekstu z wyliczeniem odsetka skumulowanego (kolumna coverage/cumulative), powstała przy pomocy narzędzia Frequency
Źródło: www.lextutor.ca/freq.
Opisane powyżej narzędzia przydadzą się nauczycielowi podczas analizy prac uczniów, a także umożliwią mu przewidywanie trudności z używaniem (lub nadużywaniem) określonych środków językowych, sprawdzanie stopnia powtarzalności słów w tekstach napisanych przez różnych uczniów oraz znajdowanie w nich cech wspólnych (świadczących o poprawności lub nie) do późniejszej analizy na forum klasy. Narzędzia te dostarczają jednak tylko danych liczbowych, które wymagają uważnej interpretacji, co na początku pracy opartej na danych językowych może być trudne.
TextSTAT (neon.niederlandistik.fu-berlin.de/en/textstat)
TextSTAT jest dość prostym programem do analizy własnych tekstów, dostępnym bez żadnych ograniczeń i obsługującym pliki w formacie .txt, .doc, .docx. Dzięki niskim wymaganiom sprzętowym i zazwyczaj bezproblemowemu działaniu również w nowszych systemach operacyjnych program jeszcze długo może być głównym narzędziem do analizy samodzielnie przygotowanych tekstów. Wielojęzyczny charakter TextSTAT, opartego na standardzie kodowania Unicode oraz umożliwiającego wybór wielu innych standardów kodowania (zwłaszcza dla alfabetów innych niż łaciński), pozwala na stworzenie własnego minikorpusu (z wybranych tekstów autentycznych lub prac uczniów). Dzięki temu nauczyciel może generować listy frekwencyjne, określać częstotliwość występowania zadanych wyrazów, porównywać ich użycie poprzez analizę konkordancji pochodzących z różnych tekstów czy dokonywać bardziej zaawansowanego zestawiania par „niepełnych” wyrazów lub fraz (tj. zawierających symbole wieloznaczne takie jak * lub ?). Program uruchamia się – bez konieczności instalacji – po rozpakowaniu pobranego ze strony pakietu (TextSTAT.exe)3. Dzięki temu z archiwum TextSTAT można korzystać z poziomu konta ucznia w szkolnej pracowni komputerowej bez ingerencji w system placówki. Do jego używania podczas lekcji zachęca również interfejs w języku polskim.
Korpusomat (www.korpusomat.pl)
Korpusomat to bezpłatne narzędzie do tworzenia własnych korpusów tekstowych online, przygotowane i udostępnione przez Instytut Podstaw Informatyki Polskiej Akademii Nauk w ramach projektu „CLARIN ERIC: Wspólne zasoby językowe i infrastruktura technologiczna”. Po bezpłatnym założeniu konta i zalogowaniu się do usługi użytkownik (nauczyciel lub uczeń) wprowadza własne pliki tekstowe, które są przechowywane na jego koncie i posłużą do stworzenia własnego korpusu. Co istotne, dla tekstów w języku polskim Korpusomat dokonuje automatycznego oznakowania fleksyjnego i przygotowuje teksty do przeszukiwania. Oznakowanie fleksyjne, dostępne tylko dla języka polskiego, umożliwia wyszukiwanie np. według części mowy lub liczby (pojedynczej/mnogiej). Korpusomat może być bardzo przydatny w przypadku tworzenia przez nauczyciela korpusu do współużytkowania przez wielu uczniów, jednak do indywidualnych prac korpusowych na tekstach własnych prostszy i łatwiejszy w obsłudze wydaje się opisany powyżej TextSTAT.
AntConc (www.laurenceanthony.net/software/antconc)
Stworzony przez Lawrence’a Anthony’ego z Waseda University w Japonii AntConc jest najbardziej zaawansowanym ze wszystkich opisywanych powyżej programów konkordancyjnych. Działa na takiej samej zasadzie jak Korpusomat i TextSTAT, pozwalając na dodanie dowolnej liczby samodzielnie przygotowanych tekstów, tworzenie list frekwencyjnych, wyszukiwanie konkordancji i analizowanie użycia słów w konkretnych kontekstach. Oprócz tego AntConc oferuje bardziej zaawansowane funkcje oparte na obliczeniach statystycznych, wykorzystywane w badaniach językoznawczych. W przeciwieństwie jednak do TextSTAT jest trudniejszy dla ucznia w obsłudze, nie ma interfejsu w języku polskim oraz wymaga instalacji na komputerze.
Rys. 2. Przykładowy zrzut z listy konkordancji dla słowa word z korpusu wielu tekstów
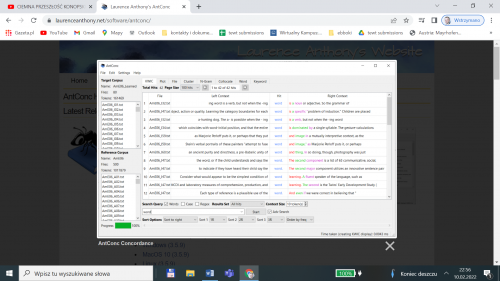
Źródło: www.laurenceanthony.net/software/antconc.
Praca z tekstem w nauczaniu sprawności pisania
Omówione programy konkordancyjne pozwalają na zastosowanie procedur językoznawstwa korpusowego w kształceniu językowym, w szczególności w ćwiczeniu sprawności pisania podczas przygotowywania do egzaminów zewnętrznych, na wyższych poziomach zaawansowania i ze starszymi uczniami. Dzięki rozpowszechnieniu darmowych narzędzi konkordancyjnych uczenie się oparte na danych językowych może być wykorzystywane zarówno przez nauczyciela w procesie przygotowywania materiałów, przykładów i kontekstów językowych na potrzeby prezentacji (tzw. miękkie podejście), jak i przez uczniów w procesie analizy tekstów samodzielnie napisanych lub wyselekcjonowanych (tzw. twarde podejście). Poniżej zostaną przedstawione propozycje wzbogacenia lekcji poświęconych nauczaniu sprawności pisania o ćwiczenia oparte na danych korpusowych.
Prezentacja częstych błędów w fazie przekazywania informacji zwrotnej
Umiejętne przekazywanie informacji zwrotnej w przypadku wypowiedzi pisemnych jest kluczowym elementem budującym świadomość językową ucznia. W tym celu nauczyciele często podsumowują błędy napotkane w sprawdzanych pracach, zwracając uwagę na to, czego należy unikać. Zebranie wszystkich prac uczniów do jednego minikorpusu pozwoli na szybkie wyekstrahowanie odpowiednich przykładów, wyeksportowanie konkordancji z błędnymi odpowiedziami do edytora tekstu lub internetowego programu celem szybkiego utworzenia interaktywnych bądź drukowanych quizów językowych. Istotna jest tu szczególnie możliwość sortowania konkordancji według kontekstu występującego z lewej lub prawej strony zadanego wyrazu, dzięki czemu uczniowie mogą zaobserwować częstotliwość standardowego i/lub poprawnego użycia słowa w stosunku do jego użycia niestandardowego i/lub błędnego.
Autokorekta prac po ich napisaniu
Starając się stworzyć jak najlepszą pracę pisemną, bardziej zaawansowani uczniowie często potrzebują wsparcia na etapie autokorekty. Zastosowanie kwerend w przygotowanym przez nauczyciela (samodzielnie lub wspólnie z uczniami) korpusie referencyjnym podobnych tekstów podczas fazy autokorekty pozwoli na porównanie struktur użytych we własnej pracy z przykładami pochodzącymi z wiarygodnych, gotowych korpusów. Wdrożenie tego typu procedury powinno mieć miejsce na lekcji – nauczyciel wprowadza zadania odwołujące się do spreparowanego minikorpusu, przeprowadzając w ten sposób uczniów krok po kroku przez czasem mało przyjazny interfejs programu i niwelując dzięki temu wrażenie „utonięcia w danych”.
W przypadku autokorekty bardzo istotne jest utrwalenie u uczniów nawyku katalogowania własnych prac pisemnych (jeżeli były wytworzone w formie cyfrowej) i dodawania ich do korpusu własnych prac. Tego typu korpus referencyjny pozwoli w przyszłości na dostrzeżenie przyrostu umiejętności językowych, stopnia zaawansowania językowego użytych struktur czy zbadania stopnia różnorodności leksykalnej napisanego tekstu (por. narzędzia Frequency lub Text-Lex Compare). Dane liczbowe dostarczone przez te narzędzia, w połączeniu z wiedzą nauczyciela nt. uczniowskiego poziomu znajomości środków językowych, pozwolą na efektywne zaprojektowanie sesji poprawiania prac. Przy korygowaniu prac pisemnych warto uczniom zwracać szczególną uwagę na słowa i zwroty sprawiające im największe trudności. Pozwoli to na formułowanie zapytań o konkordancje tych słów w szkolnym lub indywidualnym korpusie językowym i porównywanie samodzielnego ich użycia z innymi.
Wspomaganie postaw autonomicznych w procesie selekcji tekstów
Uczniowie na poziomie B1/B2, zwłaszcza nastolatkowie i dorośli, skorzystają z pewnością na włączeniu w proces selekcji tekstów do minikorpusu klasowego. Ponieważ recepcja językowa zawsze poprzedza produkcję, niezwykle pożyteczne w rozwijaniu sprawności receptywnych, przy jednoczesnym budowaniu kompetencji czytelniczej i medialnej, będzie wyznaczenie uczniom (pracującym w parach lub grupach) zadania wyszukania, ewaluacji i zgromadzenia tekstów. W zależności od stopnia ich obycia z materiałami internetowymi można zlecić „otwarte poszukiwanie skarbów” (open treasure hunts), tj. nie wskazywać domen zalecanych do skonsultowania, można wskazać wartościowe domeny bez przypisania ich do konkretnych zadań (semi-guided treasure hunts), czy wreszcie, dla najmniej zaawansowanych językowo i cyfrowo uczniów, wyznaczyć konkretne domeny, z których mają wybrać i pozyskać teksty do korpusu klasowego (fully-guided treasure hunts). Tego typu działania mogą pozytywnie wpłynąć na motywację do korzystania w późniejszym czasie z korpusu klasowego z uwagi na poczucie współodpowiedzialności za treści w nim zawarte.
Porównywanie tekstów napisanych przez różnych uczniów
W przypadku klas, w których relacje między uczniami pozwalają na stosowanie oceny wzajemnej (peer assessment), warto zaproponować porównywanie tekstów kolegów i koleżanek np. przy pomocy opisanych wyżej narzędzi analizy tekstu Text-Lex Compare lub Frequency. Z uwagi jednak na stopień skomplikowania raportów generowanych w tych programach i możliwe trudności uczniów w ich analizie, warto przygotować dla uczniów materiał poglądowy dostosowany do ich możliwości poznawczych, tj. opracować raport wcześniej, kopiując go, usuwając zbędne i zbyt zaawansowane dane, a pozostałe modyfikując w edytorze tekstu. Minianaliza wykonana automatycznie przez serwis Compleat Lexical Tutor wskaże stopień powtarzalności środków językowych, większą lub mniejszą różnorodność najczęściej używanych słów czy ich skumulowany odsetek w tekstach. Tego typu dane językowe stanowią gotowy materiał do interpretacji, dzięki czemu ocena wzajemna jest mniej subiektywna i bardziej zorientowana na faktyczne użycie środków językowych.
Zakończenie
O ile w przeszłości językoznawstwo korpusowe i uczenie się z wykorzystaniem danych językowych mogły być poza zasięgiem „zwykłego” nauczyciela i takiegoż ucznia, obecnie darmowe i stosunkowo proste narzędzia otwierają drogę do nieskrępowanego tworzenia minikorpusów i ich używania jako punktu odniesienia zarówno podczas lekcji, jak i w ramach pracy domowej. Wydaje się oczywiste, że zarówno po dwóch latach kształcenia zdalnego i hybrydowego, jak i w przypadku stacjonarnej scyfryzowanej edukacji, umiejętności komputerowe uczniów i nauczycieli w pełni umożliwią tworzenie minikorpusów. Naturalnie, podobnie jak ma to miejsce ze strategiami uczenia, niezbędny jest trening strategiczny przeprowadzony podczas lekcji pod ścisłą kontrolą nauczyciela. Wiele z narzędzi z opisanych powyżej nie było przygotowanych na potrzeby nauczania pisania w języku obcym, ale raczej analizy danych językowych, stąd ich stopień skomplikowania czy specjalistyczne określenia w języku angielskim mogą przekraczać możliwości poznawcze wielu uczniów. Dlatego tak ważne jest umiejętne stosowanie przez nauczyciela procedur i narzędzi uczenia się z wykorzystaniem danych i świadomość tego, że uczeń może „utonąć w danych” oraz zniechęcić się do tego typu aktywności.
Szczególnie sprawność pisania zyskuje nowy wymiar dzięki wdrożeniu uczniów do korzystania z korpusów przygotowywanych na potrzeby klasy lub gotowego korpusu referencyjnego. Dla uczących się na poziomach A1/A2 oraz B1/B2 autokorekta prac pisemnych jest trudna (o ile wręcz nie niemożliwa) bez wsparcia merytorycznego. O ile mało realne jest, by nauczyciel w trakcie przygotowywania pracy przez uczniów udzielił im takowego wsparcia, o tyle wyćwiczone przez nich procedury korpusowe przynajmniej częściowo wspomogą ich w procesie autokorekty i redakcji własnych tekstów.
Bibliografia
Bernardini, S. (2000), Systematising Serendipity: Proposals for Concordancing Large Corpora with Language Learners [w:] L. Burnard, T. McEnery (red.), Rethinking Language Pedagogy from a Corpus Perspective, Frankfurt: Peter Lang, s. 225–234.
Chambers, A. (2005), Integrating Corpus Consultation Procedures in Language Studies, „Language Learning & Technology”, nr 9(2), s. 111–125.
Chambers, A., O’Sullivan, Í. (2004), Corpus Consultation and Advanced Learners’ Writing Skills in French, „ReCALL”, nr 16(1), s. 158–172.
Cobb, T. (1997), Is there any Measurable Learning from Hands-on Concordancing? „System”, nr 25, s. 301–315.
Cobb, T. (1998), Breadth and Depth of Lexical Acquisition with Hands-on Concordancing, „Computer Assisted Language Learning”, nr 12(4), s. 345–360.
Cobb, T., Greaves, C., Horst, M. (2001), Can the Rate of Lexical Acquisition from Reading be Increased? An Experiment in Reading French with a Suite of Online Resources [w:] P. Raymond, C. Cornaire (red.), Regards sur la Didactique des Langues Secondes, Montréal: Éditions logique, s. 133–153.
Crystal, D. (2005), English as a Global Language, Cambridge: Cambridge University Press.
Gaskell, D., Cobb, T. (2004), Can Learners use Concordance Feedback for Writing Errors? „System”, nr 32(3), s. 301–319.
Hadley, G. (2002), Sensing the Winds of Change: An Introduction to Data-Driven Learning, „RELC Journal”, nr 33(2), s. 99–124.
Horst, M., Cobb, T., Nicolae, I. (2005), Expanding Academic Vocabulary with a Collaborative Online Database, „Language Learning & Technology”, nr 9(2), s. 90–110.
Kennedy, C., Miceli, T. (2001), An Evaluation of Intermediate Students’ Approaches to Corpus Investigation, „Language Learning & Technology”, nr 5(3), s. 77–90.
Krajka, J. (2016), Czy korpus prawdę Ci powie? O wykorzystaniu korpusów w nauczaniu języków do celów zawodowych, „Języki Obce w Szkole”, nr 3, s. 34–38.
Lee, D., Swales, J. (2006), A Corpus-Based EAP Course for NNS Doctoral Students: Moving from Available Specialized Corpora to Self-compiled Corpora, „English for Specific Purposes”, nr 25, s. 56–75.
Leńko-Szymańska, A. (2001), Passive and Active Vocabulary Knowledge in Advanced Learners of English [w:] B. Lewandowska-Tomaszczyk, P.J. Melia (red.), PALC’99. Practical Applications in Language Corpora, Frankfurt: Peter Lang, s. 287–302.
Leńko-Szymańska, A. (2005), Korpusy w nauczaniu języków obcych [w:] B. Lewandowska-Tomaszczyk (red.), Podstawy językoznawstwa korpusowego, Łódź: Wydawnictwo Uniwersytetu Łódzkiego, s. 221–239.
Lewandowska-Tomaszczyk, B. (2001), Acquisition of Lexis, Language Corpora and Foreign Language Teaching [w:] B. Lewandowska-Tomaszczyk, I. Czwenar (red.), A New Curriculum for English Studies, Piotrków: College Press.
Lewandowska-Tomaszczyk, B. (2005), Podstawy językoznawstwa korpusowego, Łódź: Wydawnictwo Uniwersytetu Łódzkiego.
Schryver, G.M., de (2002), Web for/as Corpus: A Perspective for the African Languages, „Nordic Journal of African Studies”, nr 11(2), s. 266–282.
St. John, E. (2001), A Case for Using a Parallel Corpus and Concordancer for Beginners of a Foreign Language, „Language Learning & Technology”, nr 5(3), s. 185–203.
Tribble, C. (1997), Improvising Corpora for ELT: Quick-and-dirty Ways of Developing Corpora for Language Teaching [w:] P.J. Melia, B. Lewandowska-Tomaszczyk (red.), PALC ‘97 Proceedings, Łódź: Wydawnictwo Uniwersytetu Łódzkiego, s. 106–117.
Yoon, H., Hirvela, A. (2004), ESL Student Attitudes Towards Corpus Use in L2 Writing [w:] „Journal of Second Language Writing”, nr 13, s. 257–283.
Przypisy
1 Temat ten był już poruszany we wcześniejszym artykule mojego autorstwa Czy korpus prawdę Ci powie? O wykorzystaniu korpusów w nauczaniu języków do celów zawodowych, opublikowanym w nr 3/2016 „Języków Obcych w Szkole”
2 Takich, jak np. English Corpora (english-corpora.org) dla języka angielskiego, FR ANTEXT (www.frantext.fr) dla języka francuskiego, Digitales Wörterbuch der deutschen Sprache (www.dwds.de) dla języka niemieckiego) czy Национальныйкорпус русского языка (ruscorpora.ru/new) dla języka rosyjskiego
3 TextSTAT można pobrać pod linkiem: neon.niederlandistik.fu-berlin.de/static/textstat/TextSTAT-2.9c.zip.
Artykuł został pozytywnie zaopiniowany przez recenzenta zewnętrznego „JOwS” w procedurze double-blind review.




